

- Intel compartió GPU Memory Benefits LLMS
- Los grupos VRAM expandidos permiten una ejecución más suave de cargas de trabajo de IA
- Algunos juegos se ralentizan cuando la memoria se expande
Intel ha agregado una nueva capacidad a sus sistemas ultra núcleo que se hace eco de un movimiento anterior de AMD.
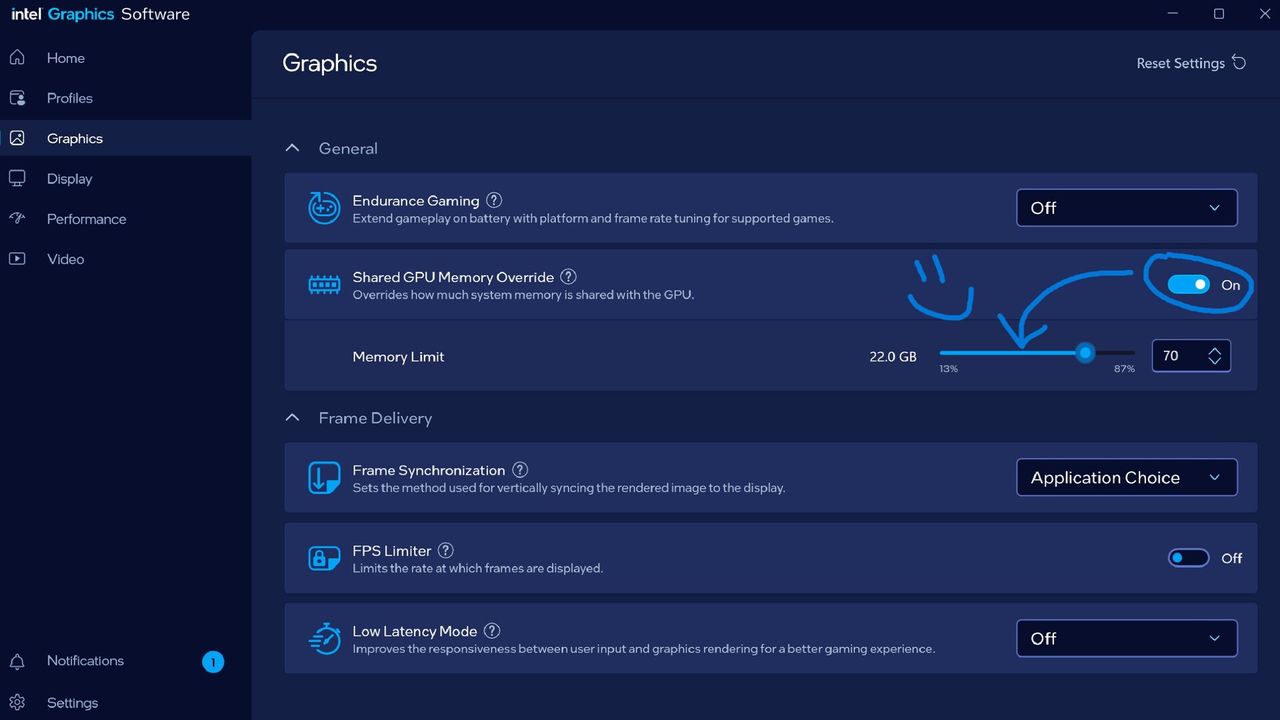
La característica, conocida como “anulación de memoria de GPU compartida”, permite a los usuarios asignar RAM del sistema adicional para su uso mediante gráficos integrados.
Este desarrollo está dirigido a máquinas que se basan en soluciones integradas en lugar de GPU discretas, una categoría que incluye muchas computadoras portátiles compactos y modelos de estación de trabajo móviles.
Asignación de memoria y rendimiento de los juegos
Bob Duffy, quien lidera los gráficos y el evangelismo de IA en Intel, confirmó la actualización y aconsejó que los últimos controladores de arco Intel se requieran para habilitar la función.
El cambio se presenta como una forma de mejorar la flexibilidad del sistema, particularmente para los usuarios interesados en herramientas de IA y cargas de trabajo que dependen de la disponibilidad de memoria.
La introducción de la memoria compartida adicional no es automáticamente un beneficio para cada aplicación, ya que las pruebas han demostrado que algunos juegos pueden cargar texturas más grandes si hay más memoria disponible, lo que en realidad puede hacer que el rendimiento disminuya en lugar de mejorar.
La “memoria de gráficos variables” anteriores de AMD se enmarcó en gran medida como una mejora del juego, especialmente cuando se combina con AFMF.
Esa combinación permitió almacenar más activos de juego directamente en la memoria, lo que a veces producía ganancias medibles.
Aunque el impacto no fue universal, los resultados variaron según el software en cuestión.
La adopción de Intel de un sistema comparable sugiere que está interesado en seguir siendo competitivo, aunque el escepticismo sigue siendo sobre cuán ampliamente beneficiará a los usuarios cotidianos.
Si bien los jugadores pueden ver resultados mixtos, aquellos que trabajan con modelos locales podrían ganar más del enfoque de Intel.
Ejecutar modelos de idiomas grandes localmente es cada vez más común, y estas cargas de trabajo a menudo están limitadas por la memoria disponible.
Al extender el grupo de RAM disponible a gráficos integrados, Intel está posicionando sus sistemas para manejar modelos más grandes que de otro modo estarían limitados.
Esto puede permitir a los usuarios descargar más del modelo en VRAM, reduciendo los cuellos de botella y mejorando la estabilidad al ejecutar herramientas de IA.
Para los investigadores y desarrolladores sin acceso a una GPU discreta, esto podría ofrecer una mejora modesta pero útil.



{kind=link}